
Qu'est-ce que Sora d'OpenAI ?

OpenAI a récemment introduit Sora, un modèle texte-vidéo qui transforme de simples prompts textuels en vidéos haute résolution. Sora se distingue des précédents modèles vidéo IA par sa cohérence, sa longueur et sa qualité photoréaliste exceptionnelles.
Pourquoi cette agitation autour de Sora ?
OpenAI, ce pionnier de l'intelligence artificielle, est réputé pour ses développements révolutionnaires en matière d'IA et de modèles génératifs, notamment la création de ChatGPT. Ce chatbot a déclenché la vague d’intérêt actuelle pour l’IA.
Sur cette base, OpenAI a récemment introduit Sora, un modèle texte-vidéo qui transforme de simples prompts textuels en vidéos haute résolution. Ce modèle s'appuie sur l'expertise développée à partir de systèmes avancés tels que GPT et DALL.E, permettant de créer des scènes détaillées avec plusieurs personnages, des mouvements variés et des détails d'arrière-plan précis.
ChatGPT est un chatbot, offrant des interactions qui imitent fidèlement la conversation humaine grâce à un puissant modèle de langage étendu basé sur l'IA générative. De même, DALL.E, un autre produit d’OpenAI, est un modèle d’IA qui permet aux utilisateurs de transformer les descriptions textuelles en images claires.


Sora se distingue des précédents modèles vidéo IA par sa cohérence, sa longueur et sa qualité photoréaliste exceptionnelles. Les efforts antérieurs en matière de vidéos générées par l’IA manquaient généralement de qualité et de réalisme, mais Sora représente une amélioration notable. Actuellement, Sora est capable de générer des vidéos d'une durée maximale d'une minute. Ce processus implique bien plus qu'une simple création d’une séquence d’images pour simuler le mouvement ; il suit également le positionnement des objets, garantissant qu'ils se déplacent d'une manière réaliste et interagissent correctement avec d'autres éléments, par exemple en se déplaçant les uns devant ou derrière les autres.
Essentiellement, Sora fait pour la génération vidéo ce que ChatGPT fait pour l'interaction textuelle et ce que DALL.E fait pour la création des images. Les utilisateurs peuvent simplement saisir un texte avec leur vision et Sora en fait une vidéo dynamique. Bien que ces vidéos manquent actuellement de son, les progrès rapides dans la génération audio et musicale basée sur l’IA suggèrent que cette fonctionnalité puisse bientôt être intégrée.
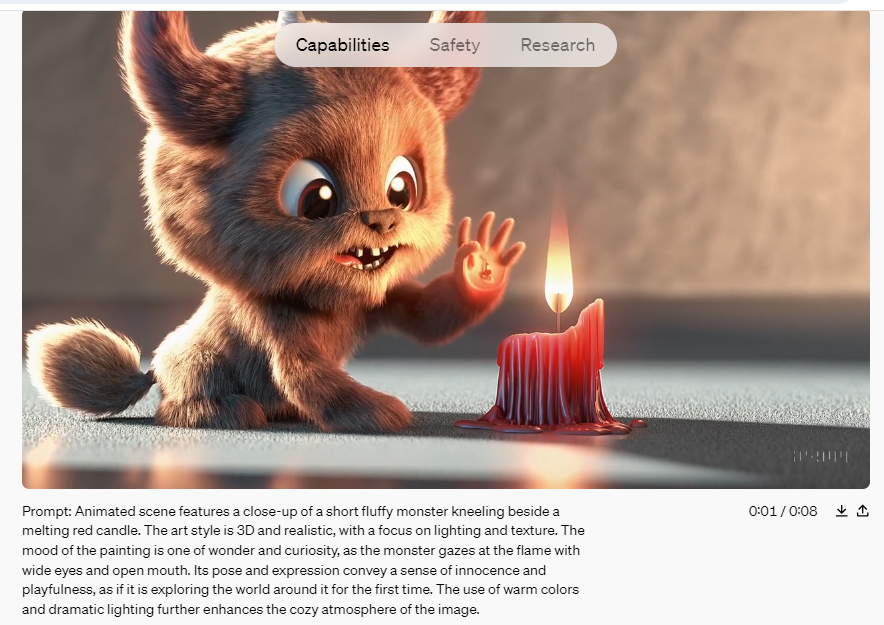
Source & Copyright: Openai.com
OpenAI a présenté Sora le 16 février, mais il n'a pas encore été mis à la disposition du grand public. L'entreprise n'autorise actuellement qu'un groupe sélectionné d'artistes et de hackers de « l'équipe rouge » à accéder à l'outil. Ces groupes explorent les avantages potentiels de la technologie et identifient toute utilisation nuisible possible. Cependant, OpenAI a partagé de nombreux exemples de vidéos de ce nouvel outil dans un post de blog annonçant le lancement, un bref rapport technique et sur le profil X (autrefois Twitter) du PDG et fondateur Sam Altman.
Comment fonctionne Sora ?
La fonctionnalité remarquable de Sora réside dans sa capacité à créer des vidéos présentant un haut degré de réalisme. Cela inclut le rendu précis des objets et des décors, ainsi que leurs mouvements et interactions au sein d'une scène donnée. Formé à l'aide de principes tels que l'éclairage réaliste, les textures naturelles et la dynamique de mouvement fluide, Sora va au-delà des simples visuels pour capturer les détails subtils qui animent une vidéo.
Semblable aux modèles d'IA texte-image comme DALL·E 3 et Midjourney, Sora fonctionne comme un programme informatique conçu pour convertir les descriptions textuelles en contenu vidéo correspondant. Plus précisément, Sora utilise un modèle de diffusion combiné à une architecture d'encodage transformant, similaire à celle de ChatGPT. Ce processus commence par un modèle de bruit aléatoire, qui est progressivement affiné par l'IA pour correspondre plus étroitement au prompt saisi.
Un aperçu technique fourni par OpenAI explique que dans les modèles de diffusion, les images sont segmentées en « patches » rectangulaires plus petites, tridimensionnelles, s'étendant dans le temps. Ces patches fonctionnent comme des « tokens » dans les grands modèles de langage, représentant des parties d'une séquence d'images plutôt que des parties de texte. L'architecture du transformateur organise ces patches, tandis que le processus de diffusion remplit le contenu détaillé de chaque patch.
Pour gérer les exigences informatiques de la génération vidéo, le modèle utilise une étape de réduction de dimensionnalité lors de la création de patches, évitant ainsi les calculs sur chaque pixel de chaque image.
Imaginez que vous commenciez avec une toile recouverte d'un bruit visuel aléatoire, semblable à celui de l'électricité statique d'un vieux téléviseur. À l’aide d’un prompt textuel spécifique, Sora transforme méthodiquement ce bruit en une image cohérente, puis en une série fluide d’images qui composent une vidéo.
Comme ChatGPT, qui interprète les mots en fonction de leur contexte pour formuler des phrases cohérentes, Sora comprend la dynamique des actions et des interactions du monde réel. L'utilisation efficace de Sora dépend de la précision et de la clarté des prompts, de la même manière que l'on interagit avec ChatGPT.
L'entraînement de Sora
OpenAI a développé Sora en l'entraînant sur une vaste gamme de vidéos accessibles au public, allant des vidéos de selfie personnelles aux longs métrages, en passant par les séquences télévisées, les scènes du monde réel, les captures de jeux vidéo et bien plus encore, pour lesquelles elle avait préalablement acquis les droits de licence. Pour permettre à Sora de mieux comprendre le contenu du monde réel, l'entreprise a utilisé un moteur de conversion vidéo-texte qui génére des légendes et des étiquettes à partir des données vidéo.

Bien qu'OpenAI n'ait pas divulgué le nombre exact de vidéos utilisées dans le processus d'entraînement, on pense qu'il s'agit de millions de vidéos. Certains experts suggèrent qu'OpenAI aurait également pu incorporer des données synthétiques provenant d'outils de développement de jeux vidéo comme Unreal Engine.
Throughout the training phase, safety experts and 'red teamers' were engaged to monitor, label, and block any potential misuse involving misinformation, bias, or hateful content through rigorous adversarial testing. The videos produced by Sora contain metadata tags identifying them as AI-generated, and there are text classifiers in place to ensure prompts comply with usage policies.
Tout au long de la phase d'entraînement, des experts en sécurité et des « équipes rouges » ont été engagés pour surveiller, étiqueter et bloquer toute utilisation abusive potentielle impliquant la désinformation, des préjugés ou des contenus haineux grâce à des tests de contradiction rigoureux. Les vidéos produites par Sora contiennent des métadonnées les identifiant comme générées par l'IA, et des classificateurs de texte sont en place pour garantir que les prompts sont conformes aux politiques d'utilisation.
Selon OpenAI, Sora sera soumis à des restrictions de contenu strictes lors de sa sortie. Ces restrictions empêcheront la génération d'images représentant des personnes réelles et interdiront les contenus incluant une violence extrême, des thèmes sexuels, des images haineuses, des ressemblances avec des célébrités ou la propriété intellectuelle d'autrui, tels que des logos et des produits. Ce sont des contraintes similaires auxquelles DALL-E 3 est confronté.
Actuellement, Sora n’est pas disponible au grand public. Après la phase de test, il sera rendu accessible à un groupe limité d'artistes visuels, de designers et de cinéastes afin d'évaluer comment ces professionnels de la création peuvent exploiter l'outil.
Il est prévu que Sora soit finalement rendu public, mais compte tenu de ses puissantes capacités, il devrait fonctionner sur un modèle payant à l'utilisation similaire à GPT.
À quoi s’attendre de Sora ?
D’après les vidéos publiées, il est évident que Sora est indubitablement supérieur à toutes les tentatives précédentes de génération de vidéos par l'IA. Sora produit désormais des vidéos présentant un éclairage précis, des reflets et des expressions humaines réalistes.
Cependant, Sora n’est pas impeccable. En observant une collection de vidéos générées par Sora, on peut facilement repérer des erreurs telles que des parties du corps qui disparaissent et réapparaissent, des personnages qui se matérialisent du néant et des pieds qui semblent planer au-dessus du sol. Actuellement, nous n’avons accès qu’à une gamme sélectionnée de vidéos fournies par OpenAI, mais une fois que le public y aura accès, des vidéos plus imparfaites pourront apparaître, mettant en évidence à la fois les forces et les limites du modèle.

Malgré ces problèmes, Sora sans aucun doute représente un développement révolutionnaire. Le potentiel de ce modèle génératif est immense. À la base, Sora permet la création de vidéos à partir de prompts textuels, même si son utilité réelle reste à voir. Même si les images générées par l’IA n’ont pas remplacé les photographes et autres professionnels de la création, elles sont de plus en plus utilisées, notamment en ligne. Les capacités de Sora pourraient potentiellement simplifier la production vidéo et la création d’effets spéciaux, réduisant ainsi le besoin de logiciels spécialisés.
Cependant, la puissance de ces technologies suscite également des inquiétudes concernant les deepfakes. Bien que les outils actuels facilitent déjà leur création, les modèles d’IA texte-vidéo comme Sora pourraient permettre à ceux qui ont de mauvaises intentions de produire encore plus facilement des deepfakes réalistes avec peu d’effort. Bien que la qualité vidéo ne soit pas encore complètement convaincante, ce n’est qu’une question de temps avant qu’elle ne s’améliore, ce qui présente des défis importants pour distinguer les images authentiques des vidéos générées par l’IA.
OpenAI a mis en place de solides garanties pour empêcher toute utilisation abusive de ses modèles, une norme qui n'est pas universellement appliquée par d'autres plates-formes utilisant des modèles open source similaires. Les prochaines années pourraient être difficiles, car la société s’adapte à la facilité et au coût croissant de la production de fausses vidéos.






 aura-t-il lieu et quel en sera le prix ?")














 et comment participer à l'Airdrop ?")