
Was ist OpenAI's Sora?


OpenAI hat kürzlich Sora eingeführt, ein Text-zu-Video-Modell, das einfache Textaufforderungen in hochauflösende Videos umwandelt. Sora unterscheidet sich von früheren KI-Videomodellen durch seine außergewöhnliche Konsistenz, Länge und fotorealistische Qualität.
Warum die ganze Aufregung um Sora?
OpenAI, ein Pionier der künstlichen Intelligenz, ist bekannt für seine bahnbrechenden Entwicklungen in den Bereichen KI und generative Modelle, einschließlich der Erstellung von ChatGPT. Dieser Chatbot löste den aktuellen Anstieg des Interesses an KI aus.
Darauf aufbauend hat OpenAI kürzlich Sora eingeführt, ein Text-zu-Video-Modell, das einfache Textaufforderungen in hochauflösende Videos umwandelt. Dieses Modell stützt sich auf das Know-how, das aus fortschrittlichen Systemen wie GPT und DALL.E entwickelt wurde, wodurch detaillierte Szenen mit mehreren Charakteren, unterschiedlichen Bewegungen und präzisen Hintergrunddetails erstellt werden können.
ChatGPT ist ein Chatbot, der Interaktionen anbietet, die die menschliche Konversation durch ein leistungsstarkes generatives KI-gesteuertes großes Sprachmodell genau nachahmen. Ganz wie DALL.E, ein weiteres Produkt von OpenAI was ein KI-Modell ist, mit dem Benutzer Textbeschreibungen in klare Bilder umwandeln können.


Sora unterscheidet sich von früheren KI-Videomodellen durch seine außergewöhnliche Konsistenz, Länge und fotorealistische Qualität. Früheren Bemühungen um KI-generierte Videos mangelte es in der Regel an Qualität und Realismus, aber Sora stellt eine bemerkenswerte Verbesserung dar. Derzeit ist Sora in der Lage, Videos zu erstellen, die bis zu einer Minute dauern. Bei diesem Prozess wird nicht nur eine Sequenz von Bildern erstellt, um Bewegungen zu simulieren. Es verfolgt auch die Positionierung von Objekten, um sicherzustellen, dass sie sich realistisch bewegen und korrekt mit anderen Elementen interagieren, z. B. sich vor oder hintereinander bewegen.
Im Wesentlichen ist Sora für die Videogenerierung das, was ChatGPT für die Textinteraktion ist und was DALL.E ist zur Bilderzeugung. Benutzer können einfach ihre Vision eingeben und Sora erweckt sie im dynamischen Videoformat zum Leben. Obwohl diesen Videos derzeit der Ton fehlt, deutet der schnelle Fortschritt bei der KI-gesteuerten Audio- und Musikgenerierung darauf hin, dass diese Funktion möglicherweise bald integriert wird.
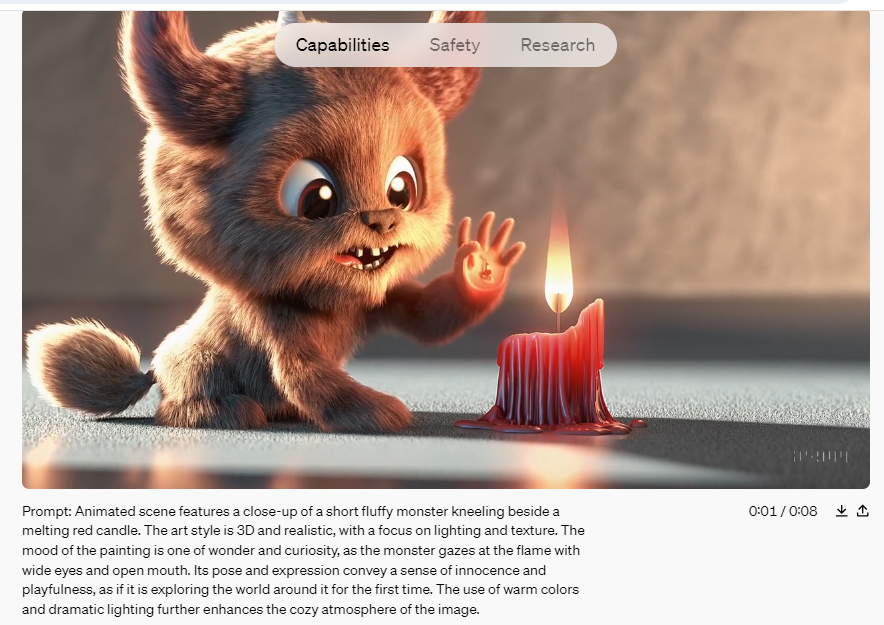
Quelle & Copyright: Openai.com
OpenAI hat Sora am 16.Februar vorgestellt, aber es wurde noch nicht der Öffentlichkeit zugänglich gemacht. Das Unternehmen erlaubt derzeit nur einer ausgewählten Gruppe von Künstlern und "Red-Team" -Hackern den Zugriff auf das Tool. Diese Gruppen untersuchen die potenziellen Vorteile der Technologie und identifizieren mögliche schädliche Verwendungen. OpenAI hat jedoch zahlreiche Beispielvideos von diesem neuen Tool in einem Blogbeitrag, der den Start ankündigt, einem kurzen technischen Bericht und auf dem X-Profil (ehemals Twitter) von CEO und Gründer Sam Altman veröffentlicht.
hier ist sora, unser Videogenerierungsmodell:https://t.co/CDr4DdCrh1
heute beginnen wir mit dem Red-Teaming und bieten einer begrenzten Anzahl von Entwicklern Zugang.@_tim_brooks @billpeeb @model_mechanic sind wirklich unglaublich; tolle Arbeit von ihnen und dem Team.
bemerkenswerter Moment.
— Sam Altman (@sama) 15. Februar 2024
Wie funktioniert Sora?
Soras bemerkenswerte Fähigkeit liegt in seiner Fähigkeit, Videos zu erstellen, die einen hohen Grad an Realismus aufweisen. Dazu gehört das präzise Rendern von Objekten und Einstellungen sowie deren Bewegungen und Interaktionen innerhalb einer bestimmten Szene. Trainiert mit Prinzipien wie realistischer Beleuchtung, natürlichen Texturen und flüssiger Bewegungsdynamik, geht Sora über einfache visuelle Elemente hinaus, um subtile Details zu erfassen, die ein Video animieren.
Ähnlich wie text-to-image KI-Modelle wie DALL·E 3 und Midjourney arbeitet Sora als Computerprogramm, das Textbeschreibungen in entsprechende Videoinhalte umwandeln soll. Genauer gesagt verwendet Sora ein Diffusionsmodell in Kombination mit einer Transformer-Codierungsarchitektur, die der von ChatGPT ähnelt. Dieser Prozess beginnt mit einem zufälligen Rauschmuster, das von der KI schrittweise verfeinert wird, um der Eingabeaufforderung näher zu kommen.
Ein technischer Überblick von OpenAI erklärt, dass in Diffusionsmodellen Bilder in kleinere rechteckige "Patches" segmentiert werden, die dreidimensional sind und sich über die Zeit erstrecken. Diese Patches funktionieren ähnlich wie "Token" in großen Sprachmodellen und repräsentieren Teile einer Bildsequenz anstelle von Textteilen. Die Transformer-Architektur organisiert diese Patches, während der Diffusionsprozess den detaillierten Inhalt für jeden Patch ausfüllt.
Um die Rechenanforderungen der Videogenerierung zu erfüllen, verwendet das Modell bei der Erstellung von Patches einen Dimensionsreduktionsschritt, wodurch Berechnungen für jedes einzelne Pixel jedes Frames vermieden werden.
Stell dir vor, du beginnst mit einer Leinwand, die von zufälligem visuellen Rauschen bedeckt ist, ähnlich wie statisch auf einem alten Fernseher. Mithilfe einer bestimmten Textaufforderung verfeinert Sora dieses Rauschen methodisch zu einem zusammenhängenden Bild und schließlich zu einer fließenden Reihe von Bildern, die ein Video ergeben.
Wie ChatGPT, das Wörter basierend auf ihrem Kontext interpretiert, um zusammenhängende Sätze zu formulieren, versteht Sora die Dynamik von Handlungen und Interaktionen in der realen Welt. Die effektive Nutzung von Sora hängt von präzisen und klaren Eingabeaufforderungen ab, ähnlich wie man mit ChatGPT interagieren würde.
Das Training von Sora erklärt
OpenAI entwickelte Sora, indem es es mit einer Vielzahl öffentlich zugänglicher Videos trainierte, darunter alles von persönlichen Selfie-Videos bis hin zu Spielfilmen, Fernsehaufnahmen, realen Szenen, Videospielaufnahmen und vielem mehr, für die es zuvor Lizenzrechte erworben hatte. Um Soras Verständnis für reale Inhalte zu verbessern, verwendete das Unternehmen eine video-to-text-Engine, die Bildunterschriften und Beschriftungen aus den Videodaten generierte.

Obwohl OpenAI die genaue Anzahl der im Trainingsprozess verwendeten Videos nicht bekannt gegeben hat, wird allgemein angenommen, dass es sich um Millionen von Videos handelt. Einige Experten vermuten, dass OpenAI möglicherweise auch synthetische Daten aus Videospielentwicklungstools wie der Unreal Engine integriert hat.
Wenn du denkst, dass OpenAI Sora ein kreatives Spielzeug wie DALLE ist, ... denk nochmal nach. Sora ist eine datengesteuerte Physik-Engine. Es ist eine Simulation vieler Welten, real oder fantastisch. Der Simulator lernt kompliziertes Rendering, "intuitive" Physik, langfristiges Denken und semantische Grundlagen, alles ... pic.twitter.com/pRuiXhUqYR
— Jim Fan (@DrJimFan) 15. Februar 2024
Während der gesamten Schulungsphase wurden Sicherheitsexperten und Red Teamer damit beauftragt, potenziellen Missbrauch mit Fehlinformationen, Voreingenommenheit oder hasserfüllten Inhalten durch strenge kontradiktorische Tests zu überwachen, zu kennzeichnen und zu blockieren. Die von Sora produzierten Videos enthalten Metadaten-Tags, die sie als KI-generiert identifizieren, und es gibt Textklassifizierer, um sicherzustellen, dass Eingabeaufforderungen den Nutzungsrichtlinien entsprechen.
Laut OpenAI wird Sora bei seiner Veröffentlichung strengen Inhaltsbeschränkungen unterliegen. Diese Einschränkungen verhindern die Erstellung von Bildern, die reale Personen darstellen, und verbieten Inhalte, die extreme Gewalt, sexuelle Themen, hasserfüllte Bilder, Abbilder von Prominenten oder das geistige Eigentum anderer, wie z.B. Logos und Produkte, enthalten. Dies sind ähnliche Einschränkungen, denen DALL-E 3 ausgesetzt ist.
Derzeit ist Sora für die breite Öffentlichkeit nicht verfügbar. Nach der Testphase wird es einer begrenzten Gruppe von bildenden Künstlern, Designern und Filmemachern zugänglich gemacht, um zu beurteilen, wie diese Kreativprofis das Tool nutzen können.
Es wird erwartet, dass Sora irgendwann veröffentlicht wird, aber aufgrund seiner leistungsstarken Funktionen wird erwartet, dass es auf einem Pay-to-Use-Modell ähnlich wie GPT arbeitet.
Was kann man von Sora erwarten?
Aus den veröffentlichten Videos geht hervor, dass Sora allen bisherigen Versuchen der KI-Videogenerierung weit überlegen ist. Sora produziert jetzt Videos mit präziser Beleuchtung, Reflexionen und lebensechten menschlichen Ausdrücken.
Sora ist jedoch nicht fehlerfrei. Wenn man eine Sammlung von Videos betrachtet, die von Sora erstellt wurden, kann man leicht Fehler erkennen, wie Körperteile, die verschwinden und wieder auftauchen, Charaktere, die sich aus dem Nichts materialisieren, und Füße, die über dem Boden zu schweben scheinen. Derzeit haben wir nur Zugriff auf eine ausgewählte Auswahl von Videos, die von OpenAI bereitgestellt werden, aber sobald die Öffentlichkeit Zugriff erhält, werden wahrscheinlich unvollkommenere Videos auftauchen, die sowohl die Stärken als auch die Grenzen des Modells hervorheben.

Trotz dieser Probleme steht außer Frage, dass Sora eine bahnbrechende Entwicklung darstellt. Das Potenzial für dieses generative Modell ist immens. Im Grunde ermöglicht Sora die Erstellung von Videos aus Textaufforderungen, obwohl seine praktische Nützlichkeit noch abzuwarten bleibt. KI-generierte Bilder haben Fotografen und andere Kreativprofis zwar nicht ersetzt, werden aber zunehmend genutzt, insbesondere online. Die Fähigkeiten von Sora könnten möglicherweise die Videoproduktion und die Erstellung von Spezialeffekten vereinfachen und den Bedarf an spezialisierter Software reduzieren.
Die Macht solcher Technologien wirft jedoch auch Bedenken hinsichtlich Deepfakes auf. Obwohl aktuelle Tools ihre Erstellung bereits erleichtern, könnten text-to-video KI-Modelle wie Sora es Menschen mit schlechten Absichten noch einfacher machen, mit geringem Aufwand realistische Deepfakes zu erstellen. Auch wenn die Videoqualität noch nicht ganz überzeugen kann, ist es nur eine Frage der Zeit, bis sie sich verbessert, was erhebliche Herausforderungen bei der Unterscheidung von KI-generierten Videos von echtem Filmmaterial mit sich bringt.
OpenAI hat starke Sicherheitsvorkehrungen getroffen, um den Missbrauch seiner Modelle zu verhindern, ein Standard, der von anderen Plattformen, die ähnliche Open-Source-Modelle verwenden, nicht universell angewendet wird. Die nächsten Jahre dürften eine Herausforderung sein, da sich die Gesellschaft an die zunehmende Leichtigkeit und Erschwinglichkeit der Produktion gefälschter Videos anpasst.





















