
What Is OpenAI's Sora?


OpenAI has recently introduced Sora, a text-to-video model that transforms simple text prompts into high-resolution videos. Sora sets itself apart from previous AI video models by its exceptional consistency, length, and photorealistic quality.
What is the Fuss Around Sora?
OpenAI, a pioneer in artificial intelligence, is renowned for its groundbreaking developments in AI and generative models, including the creation of ChatGPT. This chatbot sparked the current surge in interest in AI.
Building on this, OpenAI has recently introduced Sora, a text-to-video model that transforms simple text prompts into high-resolution videos. This model draws on the expertise developed from advanced systems like GPT and DALL.E, enabling it to create detailed scenes with multiple characters, varied motions, and precise background details.
ChatGPT is a chatbot, offering interactions that closely mimic human conversation through a powerful generative AI-driven large language model. Likewise, DALL.E another OpenAI’s product is an AI model, that allows users to transform text descriptions into clear images.


Sora sets itself apart from previous AI video models by its exceptional consistency, length, and photorealistic quality. Earlier efforts at AI-generated videos typically lacked quality and realism, but Sora represents a notable improvement. Currently, Sora is capable of generating videos that last up to a minute. This process involves more than just creating a sequence of images to simulate motion; it also tracks the positioning of objects, ensuring they move realistically and interact correctly with other elements, such as moving in front of or behind each other.
Essentially, Sora is to video generation what ChatGPT is to text interaction and what DALL.E is to image creation. Users can simply type their vision, and Sora brings it to life in dynamic video format. Although these videos currently lack sound, the rapid progress in AI-driven audio and music generation suggests that this feature may soon be integrated.
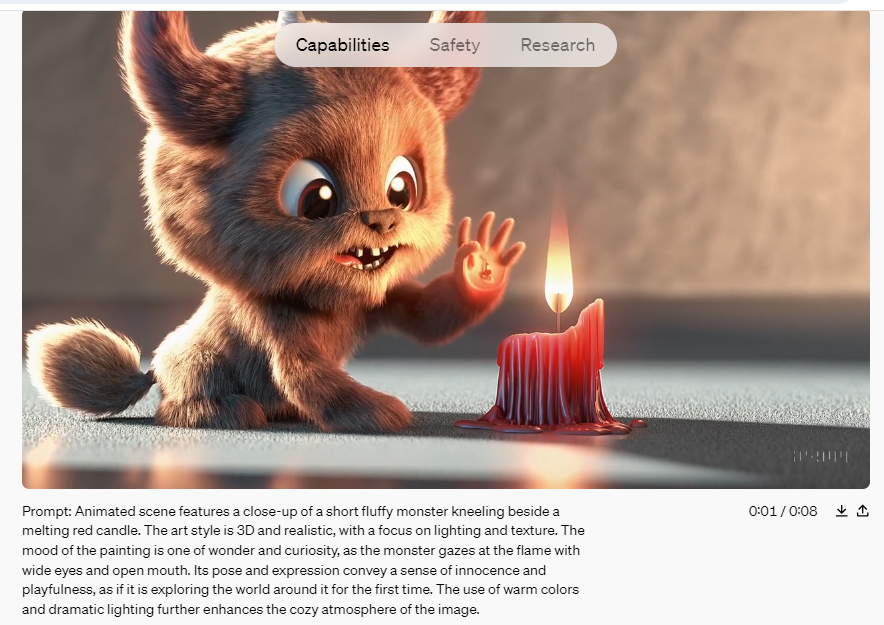
Source & Copyright: Openai.com
OpenAI introduced Sora on February 16th, but it has not yet been made available to the general public. The company is currently allowing only a select group of artists and "red-team" hackers to access the tool. These groups are exploring the technology's potential benefits and identifying any possible harmful uses. However, OpenAI has shared numerous sample videos from this new tool in a blog post announcing the launch, a brief technical report, and on the X profile (formerly Twitter) of CEO and founder Sam Altman.
How does Sora Work?
Sora's remarkable capability lies in its ability to create videos that exhibit a high degree of realism. This includes the precise rendering of objects and settings, as well as their movements and interactions within any given scene. Trained using principles such as realistic lighting, natural textures, and fluid motion dynamics, Sora goes beyond simple visuals to capture subtle details that animate a video.
Similar to text-to-image AI models like DALL·E 3 and Midjourney, Sora operates as a computer program designed to convert text descriptions into corresponding video content. More precisely, Sora utilizes a diffusion model combined with a transformer encoding architecture, which is similar to that of ChatGPT. This process begins with a random noise pattern, which is progressively refined by the AI to more closely match the input prompt.
A technical overview provided by OpenAI explains that in diffusion models, images are segmented into smaller rectangular "patches" that are three-dimensional, extending through time. These patches function akin to "tokens" in large language models, representing parts of a sequence of images rather than parts of text. The transformer architecture organizes these patches, while the diffusion process fills in the detailed content for each patch.
To manage the computational demands of video generation, the model employs a dimensionality reduction step during the creation of patches, thereby avoiding computations on every single pixel of every frame.
Imagine starting with a canvas blanketed in random visual noise, similar to static on an old television. Using a specific text prompt, Sora methodically refines this noise into a coherent image, and eventually, into a flowing series of images that make up a video.
Like ChatGPT, which interprets words based on their context to formulate coherent sentences, Sora understands the dynamics of real-world actions and interactions. Effective use of Sora hinges on providing precise and clear prompts, much as one would interact with ChatGPT.
Training of Sora Explained
OpenAI developed Sora by training it on a vast array of publicly accessible videos, including everything from personal selfie videos to feature films, television footage, real-world scenes, video game captures, and much more, for which it had previously acquired licensing rights. To enhance Sora's understanding of real-world content, the company utilized a video-to-text engine that generated captions and labels from the video data.

While OpenAI has not disclosed the exact number of videos used in the training process, it is widely believed to involve millions of videos. Some experts suggest that OpenAI might have also incorporated synthetic data from video game development tools like Unreal Engine.
Throughout the training phase, safety experts and 'red teamers' were engaged to monitor, label, and block any potential misuse involving misinformation, bias, or hateful content through rigorous adversarial testing. The videos produced by Sora contain metadata tags identifying them as AI-generated, and there are text classifiers in place to ensure prompts comply with usage policies.
According to OpenAI, Sora will be subject to stringent content restrictions upon its release. These restrictions will prevent the generation of images depicting real individuals and will prohibit content that includes extreme violence, sexual themes, hateful imagery, celebrity likenesses, or the intellectual property of others, such as logos and products. These are similar constraints faced by DALL-E 3.
Currently, Sora is not available to the general public. After the testing phase, it will be made accessible to a limited group of visual artists, designers, and filmmakers to gauge how these creative professionals can leverage the tool.
It is anticipated that Sora will eventually be made public, but given its powerful capabilities, it is expected to operate on a pay-to-use model similar to GPT.
What to Expect From Sora?
From the videos that have been released, it is evident that Sora is far superior to any previous attempts at AI video generation. Sora now produces videos featuring precise lighting, reflections, and true-to-life human expressions.
However, Sora is not flawless. Observing a collection of videos generated by Sora, one can easily spot errors such as body parts that disappear and reappear, characters that materialize out of thin air, and feet that seem to hover above the ground. Currently, we only have access to a select range of videos provided by OpenAI, but once the public gets access, more imperfect videos are likely to surface, highlighting both the strengths and limitations of the model.

Despite these issues, there is no question that Sora represents a groundbreaking development. The potential for this generative model is immense. At its most basic, Sora enables the creation of videos from text prompts, though its real-world usefulness remains to be seen. While AI-generated images have not replaced photographers and other creative professionals, they are increasingly used, especially online. Sora’s capabilities could potentially simplify video production and special effects creation, reducing the need for specialized software.
However, the power of such technologies also raises concerns about deepfakes. Although current tools already facilitate their creation, text-to-video AI models like Sora could make it even easier for those with bad intentions to produce realistic deepfakes with little effort. Although the video quality may not be completely convincing yet, it is only a matter of time before it improves, which presents significant challenges in distinguishing AI-generated videos from genuine footage.
OpenAI has put strong safeguards in place to prevent misuse of its models, a standard not universally applied by other platforms using similar open-source models. The next few years are likely to be challenging as society adjusts to the increasing ease and affordability of producing fake videos.





















