
O que é o Sora da OpenAI?


A OpenAI apresentou recentemente o Sora, um modelo de texto para vídeo que transforma simples comandos de texto em vídeos de alta resolução. O Sora se diferencia dos modelos de vídeo de IA anteriores por sua excepcional consistência, duração e qualidade fotorrealista.
Qual é o motivo de tanta agitação em torno do Sora?
A OpenAI, pioneira em inteligência artificial, é conhecida por seus desenvolvimentos inovadores em IA e modelos generativos, incluindo a criação do ChatGPT. Esse chatbot desencadeou o atual aumento do interesse em IA.
Com base nisso, a OpenAI apresentou recentemente o Sora, um modelo de texto para vídeo que transforma simples comandos de texto em vídeos de alta resolução. Esse modelo se baseia na experiência desenvolvida por sistemas avançados como o GPT e o DALL.E, o que permite criar cenas detalhadas com vários personagens, movimentos variados e detalhes precisos do plano de fundo.
O ChatGPT é um chatbot que oferece interações que se aproximam da conversação humana por meio de um modelo de linguagem grande e generativo, orientado por IA. Da mesma forma, o DALL.E, outro produto da OpenAI, é um modelo de IA que permite aos usuários transformar descrições de texto em imagens.


O Sora se diferencia dos modelos de vídeo de IA anteriores por sua excepcional consistência, duração e qualidade fotorrealista. Esforços anteriores em vídeos gerados por IA geralmente careciam de qualidade e realismo, mas o Sora representa uma melhoria notável. Atualmente, o Sora é capaz de gerar vídeos com duração de até um minuto. Esse processo envolve mais do que apenas a criação de uma sequência de imagens para simular o movimento; ele também rastreia o posicionamento dos objetos, garantindo que eles se movam de forma realista e interajam corretamente com outros elementos, como, por exemplo, movendo-se na frente ou atrás uns dos outros.
Essencialmente, o Sora é para a geração de vídeo o que o ChatGPT é para a interação de texto e o que o DALL.E é para a criação de imagens. Os usuários podem simplesmente digitar sua visão, e o Sora dá vida a ela em formato de vídeo dinâmico. Embora esses vídeos atualmente não tenham som, o rápido progresso na geração de áudio e música orientada por IA sugere que esse recurso poderá ser integrado em breve.
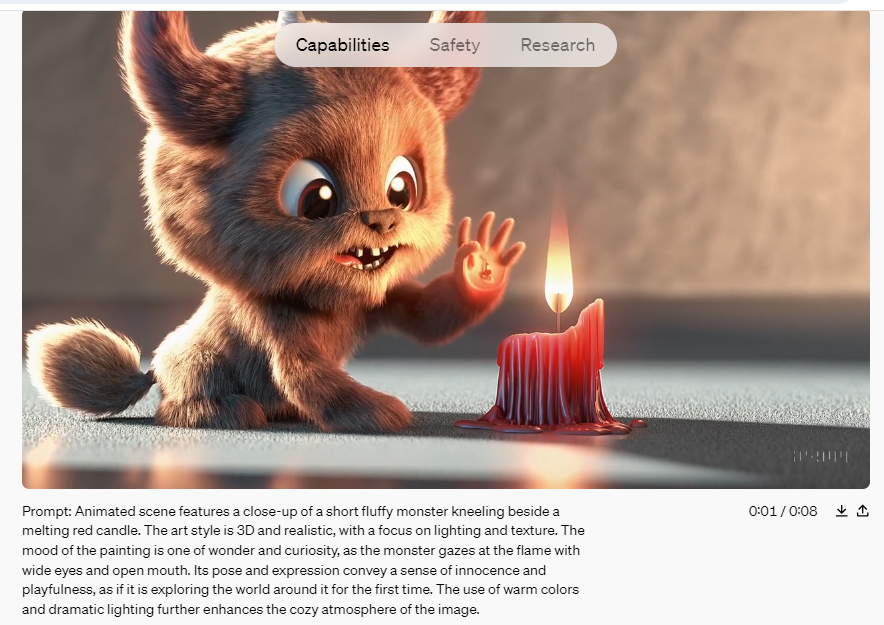
Fonte e direitos autorais: Openai.com
A OpenAI apresentou o Sora em 16 de fevereiro, mas ele ainda não foi disponibilizado para o público em geral. No momento, a empresa está permitindo que apenas um grupo seleto de artistas e hackers da "equipe vermelha" acessem a ferramenta. Esses grupos estão explorando os possíveis benefícios da tecnologia e identificando quaisquer possíveis usos prejudiciais. No entanto, a OpenAI compartilhou vários vídeos de amostra dessa nova ferramenta em uma publicação no blog anunciando o lançamento, no relatório técnico e na conta X (antigo Twitter) do CEO e fundador Sam Altman.
Como funciona o Sora?
O recurso notável do Sora está em sua capacidade de criar vídeos que exibem um alto grau de realismo. Isso inclui a renderização precisa de objetos e cenários, bem como seus movimentos e interações em uma determinada cena. Treinado com o uso de princípios como iluminação realista, texturas naturais e dinâmica de movimento fluido, o Sora vai além dos visuais simples para capturar detalhes sutis que animam um vídeo.
Semelhante aos modelos de IA de texto para imagem, como o DALL-E 3 e o Midjourney, o Sora opera como um programa de computador projetado para converter descrições de texto em conteúdo de vídeo correspondente. Mais precisamente, o Sora utiliza um modelo de difusão combinado com uma arquitetura de codificação de transformador, que é semelhante à do ChatGPT. Esse processo começa com um padrão de ruído aleatório, que é progressivamente refinado pela IA para se aproximar mais do prompt de entrada.
Uma visão geral técnica fornecida pela OpenAI explica que, nos modelos de difusão, as imagens são segmentadas em "manchas" retangulares menores que são tridimensionais e se estendem ao longo do tempo. Essas manchas funcionam de forma semelhante a "tokens" em grandes modelos de linguagem, representando partes de uma sequência de imagens em vez de partes de texto. A arquitetura do transformador organiza essas amostras, enquanto o processo de difusão preenche o conteúdo detalhado de cada amostra.
Para gerenciar as demandas computacionais da geração de vídeo, o modelo emprega uma etapa de redução de dimensionalidade durante a criação de patches, evitando assim os cálculos em cada pixel de cada quadro.
Imagine começar com uma tela coberta de ruído visual aleatório, semelhante à estática de uma televisão antiga. Usando um prompt de texto específico, Sora refina metodicamente esse ruído em uma imagem coerente e, por fim, em uma série fluida de imagens que formam um vídeo.
Assim como o ChatGPT, que interpreta palavras com base em seu contexto para formular frases coerentes, o Sora entende a dinâmica das ações e interações do mundo real. O uso eficaz do Sora depende do fornecimento de instruções precisas e claras, da mesma forma que se interage com o ChatGPT.
Treinamento do Sora explicado
A OpenAI desenvolveu o Sora treinando-o em uma vasta gama de vídeos acessíveis ao público, incluindo tudo, desde vídeos pessoais de selfies até filmes, programas de televisão, cenas do mundo real, capturas de videogames e muito mais, para os quais já havia adquirido direitos de licenciamento. Para aprimorar a compreensão do Sora sobre o conteúdo do mundo real, a empresa utilizou um mecanismo de conversão de vídeo em texto que gerou legendas e rótulos a partir dos dados do vídeo.

Embora a OpenAI não tenha divulgado o número exato de vídeos usados no processo de treinamento, acredita-se que ele envolva milhões de vídeos. Alguns especialistas sugerem que a OpenAI também pode ter incorporado dados sintéticos de ferramentas de desenvolvimento de videogames, como o Unreal Engine.
Durante toda a fase de treinamento, especialistas em segurança e "equipes vermelhas" foram contratados para monitorar, rotular e bloquear qualquer possível uso indevido que envolvesse desinformação, preconceito ou conteúdo ofensivo por meio de testes adversários rigorosos. Os vídeos produzidos pela Sora contêm tags de metadados que os identificam como gerados por IA, e há classificadores de texto para garantir que os prompts estejam em conformidade com as políticas de uso.
De acordo com a OpenAI, o Sora estará sujeito a restrições rigorosas de conteúdo quando for lançado. Essas restrições impedirão a geração de imagens que representem indivíduos reais e proibirão conteúdo que inclua violência extrema, temas sexuais, imagens de ódio, semelhanças com celebridades ou propriedade intelectual de terceiros, como logotipos e produtos. Essas são restrições semelhantes às enfrentadas por DALL-E 3.
Atualmente, o Sora não está disponível para o público em geral. Após a fase de testes, ela será disponibilizada a um grupo limitado de artistas visuais, designers e cineastas para avaliar como esses profissionais criativos podem aproveitar a ferramenta.
Prevê-se que o Sora acabará se tornando público, mas, devido aos seus recursos avançados, espera-se que ele opere em um modelo de pagamento para uso semelhante ao GPT.
O que esperar do Sora?
Com base nos vídeos que foram lançados, é evidente que o Sora é muito superior a qualquer tentativa anterior de geração de vídeo com IA. O Sora agora produz vídeos com iluminação precisa, reflexos e expressões humanas realistas.
Entretanto, o Sora não é perfeito. Observando uma coleção de vídeos gerados pela Sora, é possível identificar facilmente erros como partes do corpo que desaparecem e reaparecem, personagens que se materializam do nada e pés que parecem pairar acima do solo. No momento, só temos acesso a uma gama seleta de vídeos fornecidos pela OpenAI, mas assim que o público tiver acesso, é provável que surjam mais vídeos imperfeitos, destacando os pontos fortes e as limitações do modelo.

Apesar desses problemas, não há dúvida de que o Sora representa um desenvolvimento inovador. O potencial desse modelo generativo é imenso. Em sua forma mais básica, o Sora permite a criação de vídeos a partir de instruções de texto, embora sua utilidade no mundo real ainda esteja para ser vista. Apesar de as imagens geradas por IA não terem substituído os fotógrafos e outros profissionais criativos, elas são cada vez mais usadas, especialmente on-line. Os recursos do Sora podem simplificar a produção de vídeo e a criação de efeitos especiais, reduzindo a necessidade de software especializado.
No entanto, o poder dessas tecnologias também gera preocupações com relação às deepfakes. Embora as ferramentas atuais já facilitem sua criação, os modelos de IA de texto para vídeo, como o Sora, podem facilitar ainda mais a produção de deepfakes realistas com pouco esforço para aqueles que têm más intenções. Embora a qualidade do vídeo ainda não seja totalmente convincente, é apenas uma questão de tempo até que ela melhore, o que apresenta desafios significativos para distinguir vídeos gerados por IA de filmagens genuínas.
A OpenAI implementou fortes salvaguardas para evitar o uso indevido de seus modelos, um padrão que não é aplicado universalmente por outras plataformas que usam modelos de código aberto semelhantes. É provável que os próximos anos sejam desafiadores à medida que a sociedade se ajusta à crescente facilidade e acessibilidade da produção de vídeos falsos.





















 e como participar do airdrop?")